robots.txtに関するQ&A
初心者向けに、robots.txtとは何かを、Q&A形式でまとめました。
robots.txtとは?
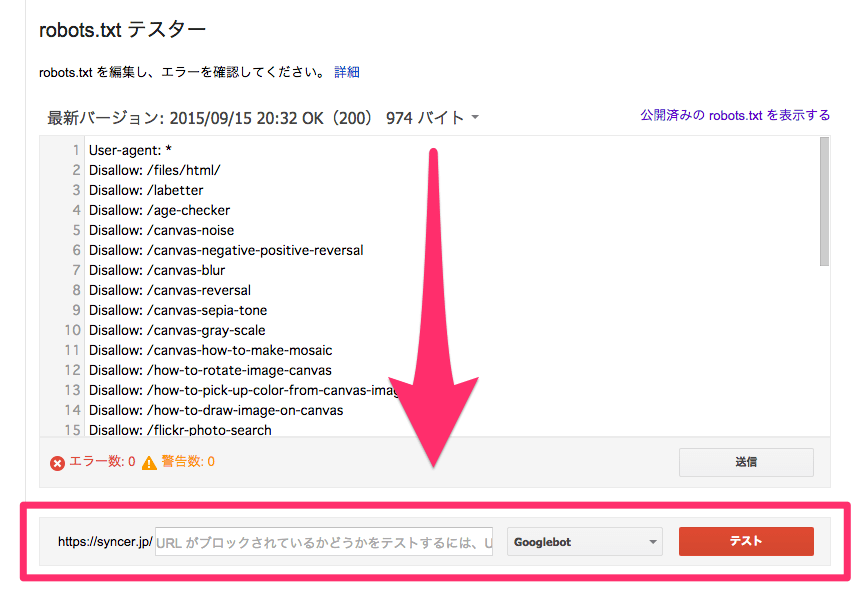
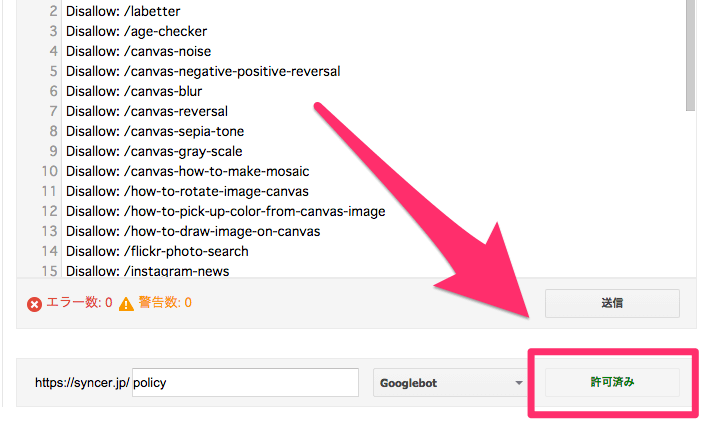
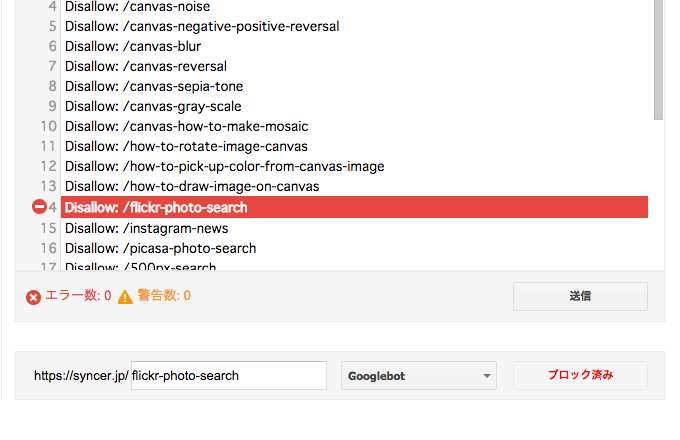
robots.txtとは、GoogleやYahoo!などといった、自サイトの情報を取得(クロール)するプログラム(クローラー)を制御するためのテキストファイルです。例えば、特定のファイルや、ディレクトリをクロール禁止に指定することで、それらの関連ページや画像などを検索エンジンにインデックスさせないようにする、などといったことができます。
何を覚えればいい?
robots.txtの設置方法は簡単です。よほど特殊な事情がない限り、「ここにアクセスしないでね」という記述方法だけを覚えておけば十分です。細かく書いたからといって、SEO上、有利、不利になるようなことはないので安心して下さい。強いて言うなら、細かく書き過ぎて間違った制御をした場合に不利になります。
作成するのにソフトは必要?
必要ありません。robots.txtは、ただのテキストファイルなので、メモ帳があれば十分です。
どこに設置すればいいの?
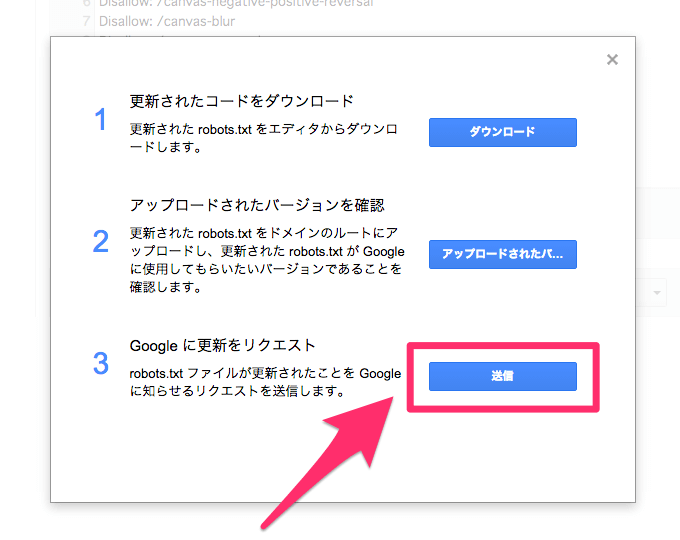
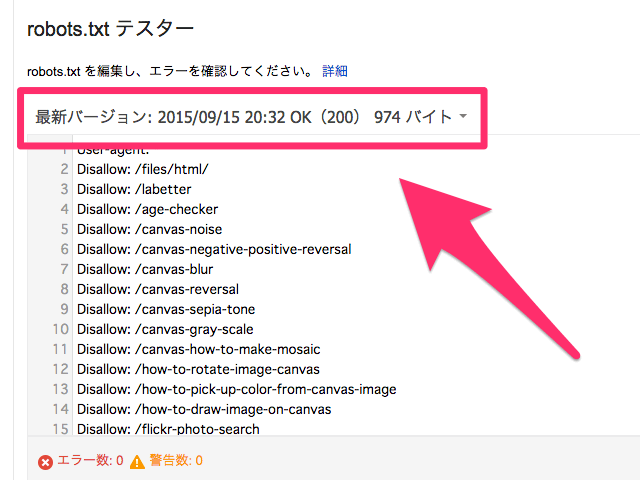
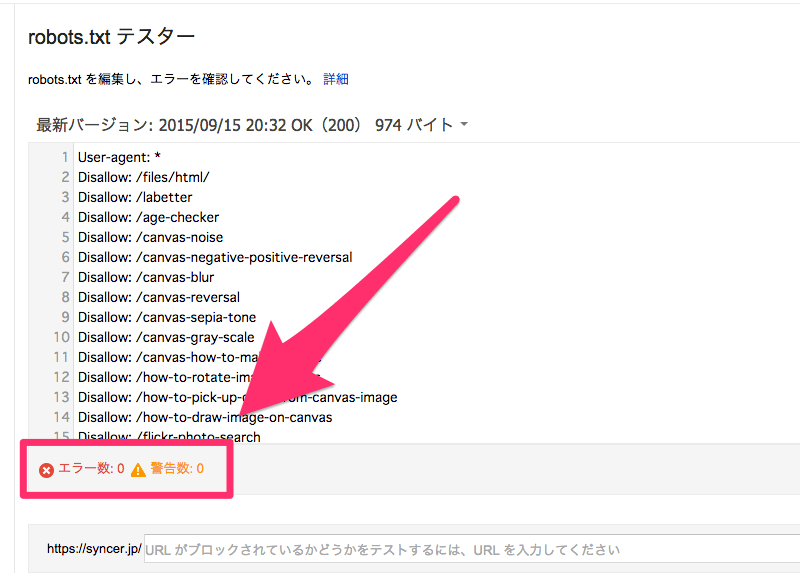
最上位のディレクトリに、robots.txtという名前のテキストファイルで設置しておけば、クローラーが勝手に参照してくれます。このサイトの場合だったら、https://syncer.jp/robots.txt の位置ですね。robotではなく、robotsであることに注意して下さい。
命令がない場合も設置した方がいい?
設置するべきです。robots.txtは、クローラーに対する規約、説明書のようなものです。「何も制約はないよ」という説明を、robots.txtを通してクローラーに明示して下さい。なお、Googleのことだけを考えるなら、必要ありません。
サイトのページをすべてクロールさせたい場合は、robots.txt ファイルを作成する必要はありません。
強制力はないの?
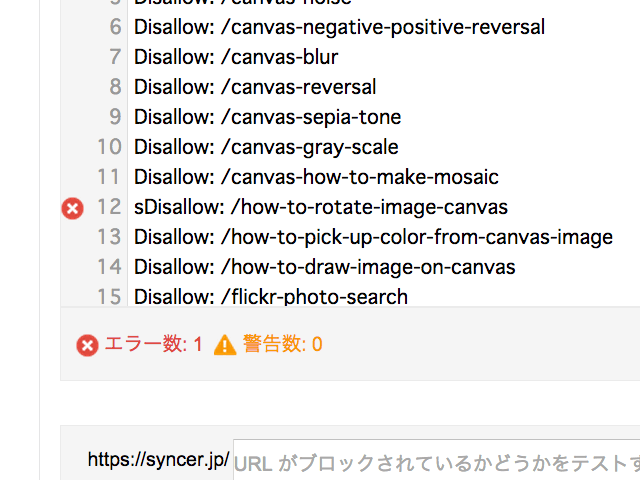
robots.txtは、.htaccessのような強制力を持ちません。一般的に、Googleなどの信用できるサイトのクローラーは、クロールを開始する前にrobots.txtの内容を確認し、それに従います。行ってはいけない場所には行かないわけですね。しかしながら、これらはあくまでも任意に従っているだけです。世の中には行儀の悪いクローラーがたくさんいて、それらはrobots.txtの内容を無視して自分が取得したい情報を取得します。そういったクローラーに対しては、robots.txtではなく、.htaccessなどで強制的に排除する必要があることを理解しておいて下さい。